π*0.6 and RECAP: Teaching Robots to Learn From Their Mistakes
Imagine teaching someone to drive by only showing them videos of perfect driving. They'd learn the ideal path, the smooth turns, the gentle braking - but what happens when they make their first mistake? Without ever experiencing errors and corrections, they'd be completely unprepared to recover.
This is precisely the challenge facing Vision-Language-Action (VLA) models in robotics. These powerful systems, trained on thousands of hours of expert demonstrations, can learn to perform complex tasks - but they hit a fundamental ceiling: they can only be as good as their training data, and they never learn how to recover from their own mistakes.
Physical Intelligence's π*0.6 introduces RECAP (RL with Experience and Corrections via Advantage-conditioned Policies), an elegant solution that enables these models to learn from both successes and failures - without requiring the mathematical machinery that standard reinforcement learning demands.
The Background: Why We Need Something New
Before diving into RECAP, let's understand the foundation it builds upon. If you're unfamiliar with flow matching or Physical Intelligence's approach to robotics, I recommend reading my previous articles on Flow Matching and Physical Intelligence first.
The Model: π0.6 and Flow Matching
π*0.6 builds on the π0.6 architecture:
- Gemma 3 4B VLM backbone for vision-language understanding
- 860M parameter action expert for generating continuous robot actions
- Multi-modal outputs: sub-task text, discretized actions (FAST tokens), and continuous action chunks at 50Hz
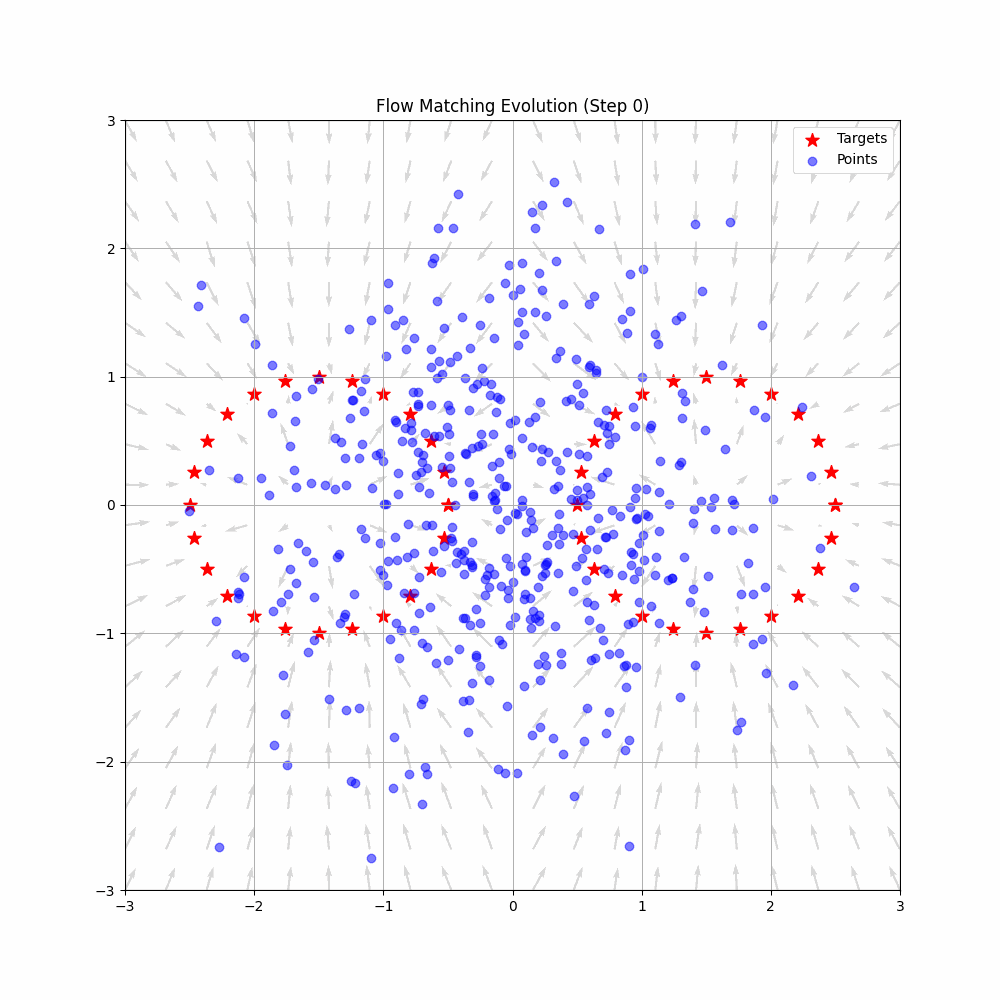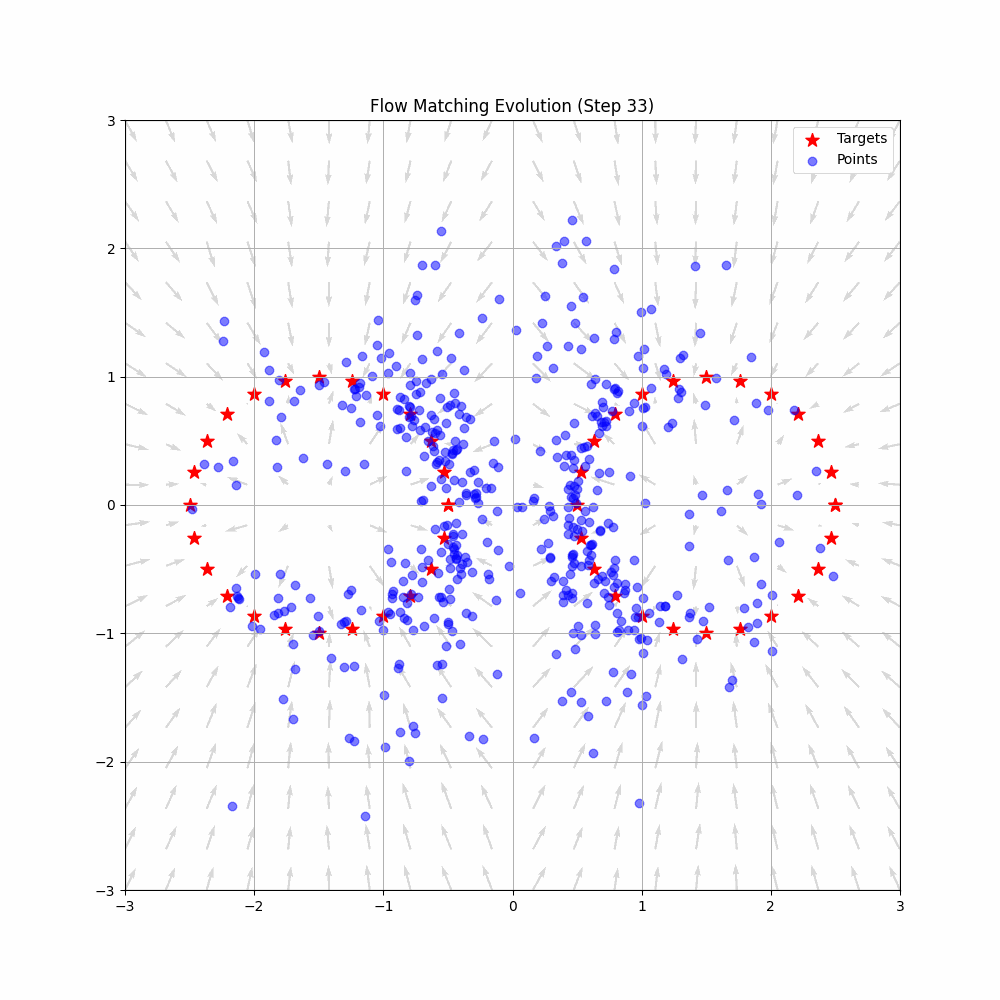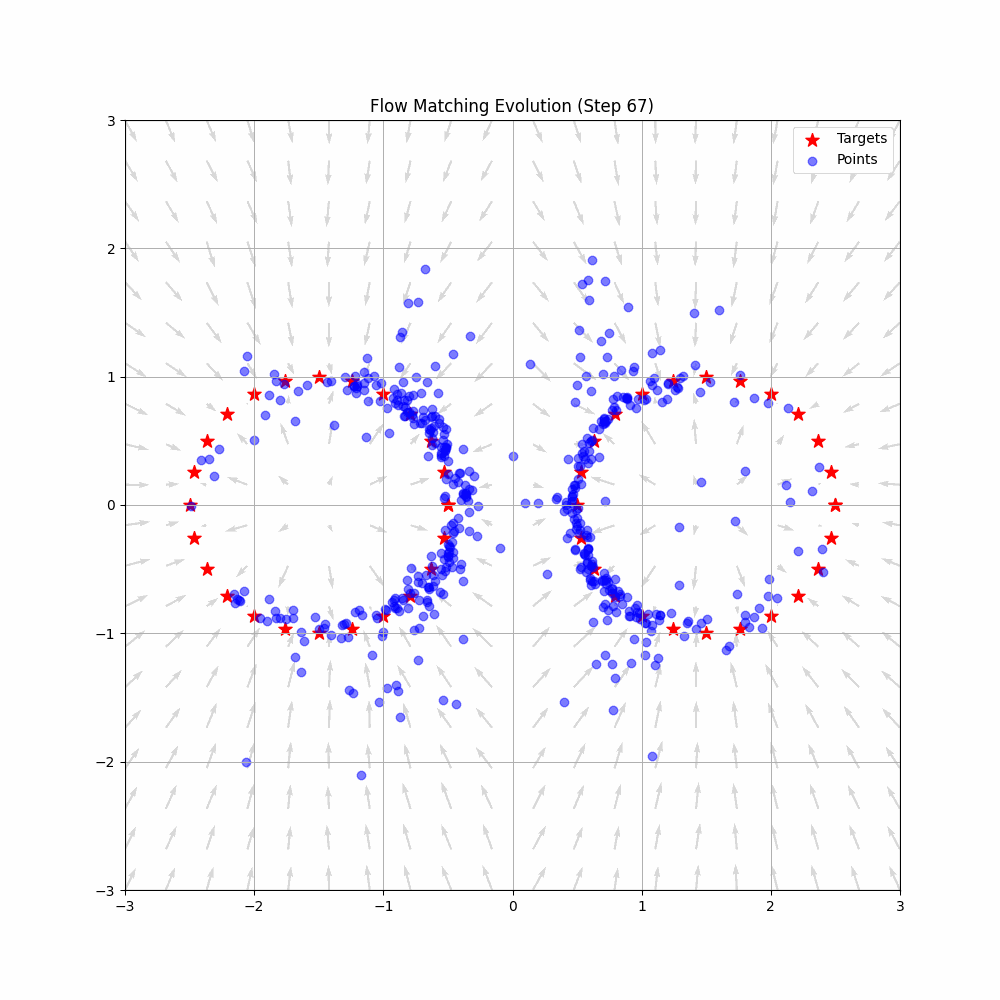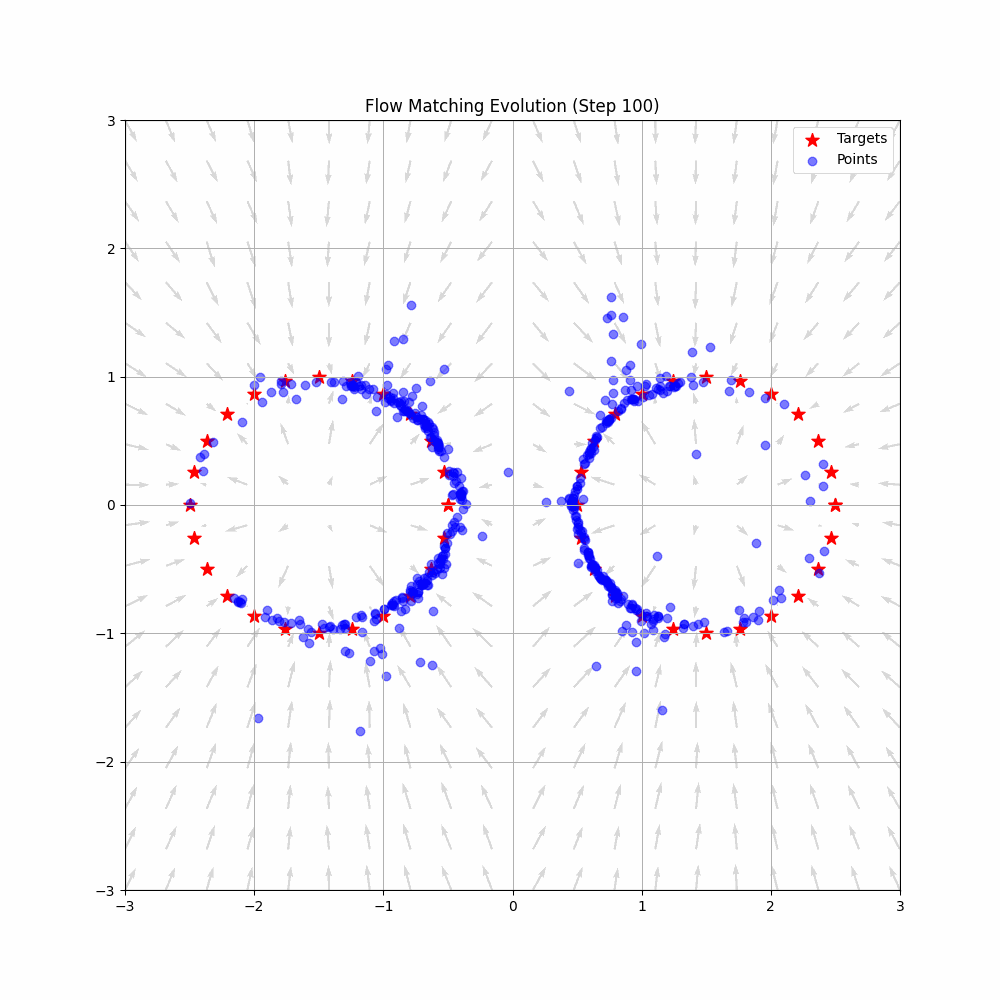
The action expert uses flow matching, a generative modeling technique related to diffusion models. Flow matching learns to transform noise into actions by modeling a continuous "flow" from a simple distribution to the target action distribution.
Key insight: Flow matching learns to transform noise into actions through a continuous "flow" - like sculpting random clay into a precise shape through gradual refinement. This produces smooth, natural robot movements rather than jerky discrete actions.
Model Evolution
The π0 family has evolved through several iterations:
The key addition for RL: an advantage indicator input that modulates action generation. This simple addition (a text token indicating whether the current context represents "positive" or "negative" behavior) is what enables RECAP.
The Real Problem: Demos Aren't Enough
VLA models like π0 are trained on demonstrations - humans teleoperating robots to show them what to do. But this approach hits a fundamental ceiling:
- You can't surpass your teacher - The policy inherits all the imperfections of the demo data
- Compounding errors - Small mistakes accumulate; a 1% error per step becomes catastrophic over 100 steps
- No self-correction - The model never sees failure, so it can't recognize or recover from mistakes
The analogy: You can watch tennis tutorials forever, but you won't improve beyond a certain point without actually playing. Robots need the same thing - they need to learn from their own attempts.
The question is: How do we enable robots to improve through practice?
Why Standard RL Doesn't Work Here
The natural answer would be reinforcement learning - let the robot try, get rewards, and improve. But there are two major obstacles:
-
No log-probabilities: Standard RL algorithms (PPO, SAC) require computing for policy gradients. Flow matching models don't provide these - they generate actions through iterative denoising with no explicit probability distribution to query.
-
Sample inefficiency: Even if log-probs were available, policy gradient methods are notoriously sample-hungry. Real robots can't afford millions of rollouts to learn a single task.
So the paper needs a method that:
- Enables learning from on-robot experience (the real goal)
- Doesn't require log-probabilities (technical constraint #1)
- Is sample-efficient enough for real-world robotics (technical constraint #2)
This is exactly what RECAP provides.
The Core Insight: Learning Contrast, Not Just Imitation
RECAP's key insight is beautifully simple: instead of computing gradients through log-probabilities, convert the RL problem into conditional supervised learning.
Think about how humans learn complex skills. A tennis coach doesn't just show you perfect serves - they show you what you're doing wrong and what you should do instead. The contrast between good and bad is as valuable as seeing good alone.
RECAP applies this principle:
- Training: Show the model both successful and failed actions, tagged as "Advantage: positive" or "Advantage: negative"
- Inference: Always condition on "positive" to generate good actions
The RECAP Training-Inference Loop: collect → label → train → deploy → repeat
RECAP Step by Step
Let's walk through each component of RECAP with intuitive explanations.
Step 1: Training a Value Function
Before we can say which actions are "good" or "bad," we need a way to measure outcomes. RECAP uses a value function that predicts: "From this state, how many steps until task success?"
Value function intuition: Think of it as a GPS that tells you not just where you are, but how far you are from your destination. V(state) = -5 means "expect 5 more steps to success". V(state) = -100 means "you're way off course".
The beauty of this approach is its simplicity. You don't need complex reward engineering - just binary success/failure labels at the end of each episode. The value function learns to predict distance-to-success from images and language commands using standard supervised learning.
🔧Technical Deep-Dive: Value Function Training▶
Reward Structure (assigned retroactively after episode ends):
For a successful episode:
For a failed episode:
The value function is trained via supervised learning: given an image and language command, predict the discretized return value using cross-entropy loss.
Step 2: Computing Advantage
Advantage answers a simple question: "Was this action better or worse than what we expected?"
Concrete example:
After computing advantages, RECAP binarizes them using a threshold chosen so approximately 30% of actions are labeled "positive". This creates a clear contrast signal without being too selective.
Step 3: Advantage-Conditioned Training
Here's where the magic happens. Each training example gets an advantage label prepended as a text token:
What the model learns:
- "When I see 'positive', generate actions like the successful examples"
- "When I see 'negative', generate actions like the failed examples"
- The model builds an internal representation of what makes actions "good" vs "bad"
The contrast principle: Learning what NOT to do is as valuable as learning what to do. A model trained on only successes might accidentally produce failure-like patterns. A model that knows both can actively avoid the bad patterns.
Why This Works: The Contrast Principle
The model learns contrast - the difference between good and bad actions in the same situations:
| Approach | What model learns |
|---|---|
| Train on good data only | "Here's what success looks like" |
| RECAP (train on all with labels) | "Here's what success looks like AND here's what failure looks like" |
Learning what NOT to do is as valuable as learning what to do. The model can actively avoid failure patterns rather than just hoping to hit success patterns.
Analogy - Weak vs Strong Teacher:
| Approach | What the student learns |
|---|---|
| Weak teacher: "Here are 100 correct solutions. Learn from them." | Student doesn't know what mistakes to avoid |
| Strong teacher: "Here are 100 correct solutions labeled 'good', and 50 incorrect ones labeled 'bad'. When I ask for 'good', give me something like the first group." | Student learns both what TO do and what NOT to do |
🔧Technical Deep-Dive: Dropout and Classifier-Free Guidance▶
A crucial design choice: 30% dropout on the advantage indicator during training.
This means 30% of the time, the model sees training examples without any advantage label. Why?
- Prevents over-reliance: The model can't just memorize "positive = this exact action"
- Enables classifier-free guidance: At inference, you can interpolate between conditioned and unconditioned outputs for stronger guidance
- Maintains base capability: The model can still generate reasonable actions even without the indicator
The classifier-free guidance formula:
Where γ > 1 amplifies the "positive" conditioning effect.
Step 4: Deployment with "Positive" Always
At inference time, the strategy is delightfully simple: always input "Advantage: positive".
The model, having learned the contrast between good and bad actions, will sample from the "positive" distribution - producing actions similar to successful training examples and avoiding patterns associated with failures.
| Behavioral Cloning | RECAP | |
|---|---|---|
| Training data | Good examples only | Good + bad with labels |
| Concept of failure | ❌ None | ✅ Learns what to avoid |
📐Theoretical Justification▶
For a reference policy π_ref, the optimal improved policy has the form:
When β=1, this can be rewritten as conditioning on an improvement indicator:
By training the policy to model the conditional distribution (with advantage indicator), sampling with "positive" directly gives improved actions. This provides theoretical grounding for why the simple labeling approach actually works.
The Critical Role of Human Interventions
Here's an important truth about RECAP: it cannot explore on its own. The policy can only improve toward the best actions already in the dataset. If no human ever demonstrated recovery from a particular failure mode, RECAP can't discover it.
This is where human interventions become essential.
How Interventions Work
During autonomous robot operation, a human operator monitors a live video feed. When the robot is about to fail, the human can take over the controls and demonstrate the correct recovery action.
The process:
- Robot runs autonomously
- Human operator watches a live feed
- When robot is about to fail, human grabs the controller ⚠️
- Human teleoperates the correction (demonstrates recovery)
- Human releases control, robot continues
- Episode ends, gets labeled success/failure
How Intervention Data is Labeled
Why Interventions Are Labeled "Positive"
Critical insight: ALL human intervention actions are FORCED to "positive", regardless of what the computed advantage would be.
Why? Because human corrections are assumed to be expert-quality demonstrations of recovery. Even if the value function thinks the state is hopeless (very negative expected return), the human's correction shows a valid path forward. By labeling these as "positive," RECAP learns:
"When you find yourself in this bad situation, do what the human did."
Why Interventions Are Critical
RECAP cannot explore optimally on its own. Human interventions expand the space of "good" actions:
Without Interventions
- Policy stuck in local pattern
- Collects similar data repeatedly
- Trains on same patterns
- NO IMPROVEMENT ✗
With Interventions
- Policy about to fail
- HUMAN DEMONSTRATES RECOVERY
- Recovery actions FORCED TO 'POSITIVE'
- EXPANDS good action distribution ✓
Interventions expand the solution space: Without interventions, RECAP can only improve within behaviors the robot already knows. Interventions inject new "good" behaviors into the dataset, especially for recovery situations the robot would never reach on its own.
🔧Technical Deep-Dive: Intervention Labeling▶
Consider an episode with intervention at timesteps 3-5:
| Timestep | Actor | Advantage Label |
|---|---|---|
| t=0 | Robot | Computed normally (could be + or -) |
| t=1 | Robot | Computed normally |
| t=2 | Robot | Computed normally (probably negative - led to near-failure) |
| t=3 | Human | Forced to "positive" |
| t=4 | Human | Forced to "positive" |
| t=5 | Human | Forced to "positive" |
| t=6 | Robot | Computed normally |
The robot's pre-intervention actions might get negative labels (they led to a situation requiring intervention), while the human's corrections get positive labels, teaching the contrast between "what went wrong" and "how to fix it."
The Complete Training Pipeline
Let's put it all together. RECAP training happens in two phases:
Phase 1: Pre-training
Train on a large, diverse dataset of demonstrations to build general capabilities:
- Train value function V_pre on diverse demonstration dataset
- Train policy π_pre with advantage conditioning
This gives you a capable base model that understands a wide variety of tasks.
Phase 2: Per-Task Improvement Loop
For each specific task you want to master, the training follows an iterative process:
RECAP Improvement Cycle: repeat for k iterations
Detailed Iteration Flow
🔧Technical Deep-Dive: Handling Heterogeneous Data▶
RECAP elegantly handles mixed data sources:
| Data Source | Advantage Label Strategy |
|---|---|
| Initial demonstrations | Computed from value function |
| Autonomous rollouts (robot) | Computed from value function (can be + or -) |
| Human interventions | Forced to "positive" (trust the expert) |
Key design choices:
- Sparse rewards: Only success/failure labels needed - no complex reward shaping
- Monte Carlo value estimates: Simple and stable (though less sample-efficient than off-policy methods)
- ~30% positive threshold: Ensures meaningful contrast between positive and negative
- Retrain from pre-trained checkpoint: Prevents drift over multiple iterations
Results: Does It Actually Work?
The empirical results are compelling:
| Task | Before RECAP | After RECAP | Improvement |
|---|---|---|---|
| Diverse Laundry Folding | 1x throughput | 2.1x throughput | +110% |
| Espresso Making | 1x throughput | 2.3x throughput | +130% |
| Box Assembly | 65% success | 90% success | +25 points |
Real-World Deployment
Beyond benchmark improvements, π*0.6 demonstrated practical viability:
- 13 hours of continuous espresso making in deployment
- 2+ hours folding novel laundry items in new home environments
- Real factory box assembly operations
These aren't cherry-picked demos - they represent sustained, practical deployment with meaningful throughput improvements.
Understanding RECAP's Limitations
It's crucial to understand what RECAP is and isn't. This intellectual honesty helps set appropriate expectations.
What RECAP Actually Is
RECAP is fundamentally filtered behavioral cloning:
- Collect data (demos + autonomous rollouts + interventions)
- Label actions as "good" or "bad" based on advantage
- Train policy to generate "good" actions when prompted
This is different from true RL algorithms that optimize expected return through policy gradients.
What It Converges To
| Method | Converges To |
|---|---|
| Behavioral Cloning | Average of all demonstration actions |
| RECAP | Best actions in dataset + all human interventions |
| True RL (PPO, SAC) | Optimal policy (with sufficient exploration) |
Important caveat: RECAP CANNOT discover the globally optimal policy. It can only become as good as the best behaviors in its dataset. If no one ever demonstrated the optimal technique, RECAP won't find it.
Why It Cannot Find the Optimal Policy
No Systematic Exploration
RECAP only learns from states the policy happens to visit. It doesn't actively seek out informative experiences.
Ex: A robot that never attempts left-handed grasps won't learn them
Relative Advantage
The top 30% of mediocre actions are still labeled 'positive.' If your dataset only contains suboptimal behaviors, RECAP optimizes toward those.
Ex: 50% spill rate becomes 'positive' if 70% spill is average
Distribution Shift
If the improving policy avoids certain states, it stops collecting data there - potentially missing better strategies.
Ex: Policy avoids risky shortcuts that might be optimal
No Improvement Guarantee
Unlike policy gradients, there's no formal proof that training on positive-advantage actions improves expected return.
Ex: Theoretical gap between filtering and optimization
The Relativity Problem Illustrated
Why RECAP Matters Despite Limitations
Given these caveats, why is RECAP valuable? Because it solves a real problem that had no good solution:
True RL (PPO, SAC)
- ❌ Doesn't work with flow matching
- ✓ Systematic exploration
- ✓ Converges to optimal (under assumptions)
- ⚠️ Often unstable
- ⚠️ Sample inefficient
RECAP
- ✓ Works with flow matching
- ⚠️ Limited exploration (+ interventions)
- ⚠️ Converges to best in dataset
- ✓ Very stable (just supervised learning)
- ✓ Higher sample efficiency
The practical reality: For flow-matching VLAs, the choice isn't between RECAP and optimal RL - it's between RECAP and no improvement at all. And RECAP delivers meaningful, deployable improvements.
Connections to Broader Themes
RECAP fits into a larger story about how we train autonomous systems. In my article on closed-loop training for autonomous driving, I explored how systems need to experience consequences to learn robust behaviors.
RECAP embodies this principle for robotic manipulation:
- Closed-loop experience: The robot's own rollouts create training data
- Error exposure: Negative-advantage labeling teaches what failure looks like
- Recovery learning: Human interventions demonstrate correction strategies
The key difference from autonomous driving approaches is RECAP's clever workaround for the log-probability problem - converting what would be a policy gradient update into conditional supervised learning.
Practical Limitations
Before concluding, it's important to acknowledge RECAP's practical constraints:
- Not fully autonomous: Requires human labeling, interventions, and resets
- Limited exploration: Relies on policy stochasticity and human interventions to discover new behaviors
- Iterated offline updates: Not fully online RL - must collect batches, retrain, redeploy
- Requires human judgment: Success/failure labels and intervention timing depend on human operators
These limitations don't diminish RECAP's value - they define its operating envelope. For teams with human operators who can provide interventions and labels, RECAP offers a practical path to continuous improvement.
Conclusion: The Elegant Workaround
RECAP represents a pragmatic breakthrough: enabling RL-style improvement where the mathematical machinery of standard RL doesn't apply. Its core insight - teach contrast through labels, then always request the "good" side - is elegant in its simplicity.
The results speak for themselves: 2x throughput improvements on complex real-world tasks, 13+ hours of continuous deployment, and practical factory operations. These aren't incremental gains; they're the difference between laboratory demonstrations and practical robotics.
But RECAP also teaches us intellectual humility. It's not optimal RL; it's filtered behavioral cloning with a clever interface. Understanding this distinction helps us appreciate both what it achieves and where future improvements might come from.
The path toward truly optimal robot learning remains open. But for now, RECAP shows that when the standard tools don't fit, creative reformulation can unlock practical progress.
References
- Physical Intelligence (2025): π*0.6: A VLA That Learns From Experience (arXiv:2511.14759)
- Physical Intelligence Blog: π*0.6 Announcement
- Related Reading:
- Flow Matching Explained - Technical foundation for π0's action generation
- Physical Intelligence in Robotics - Background on PI's approach to embodied AI
- Closed-Loop Training for Autonomous Driving - Related concepts in autonomous systems