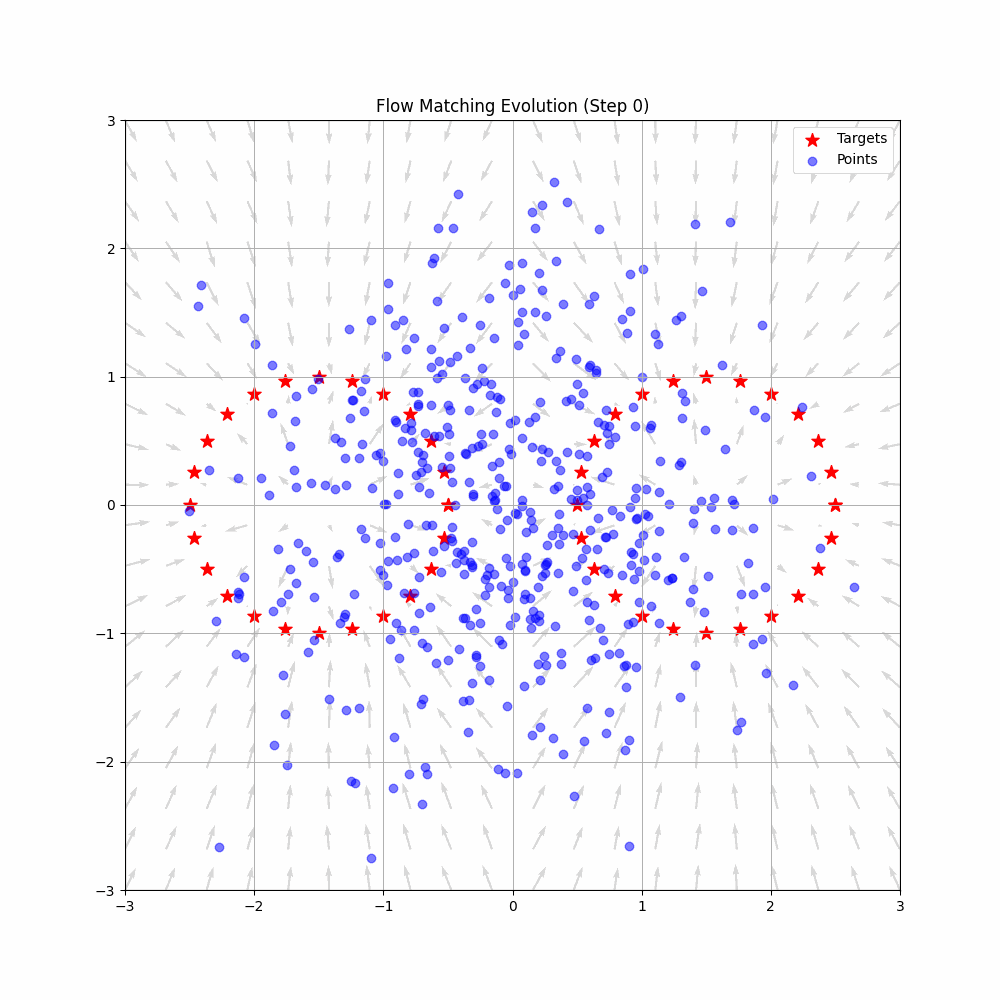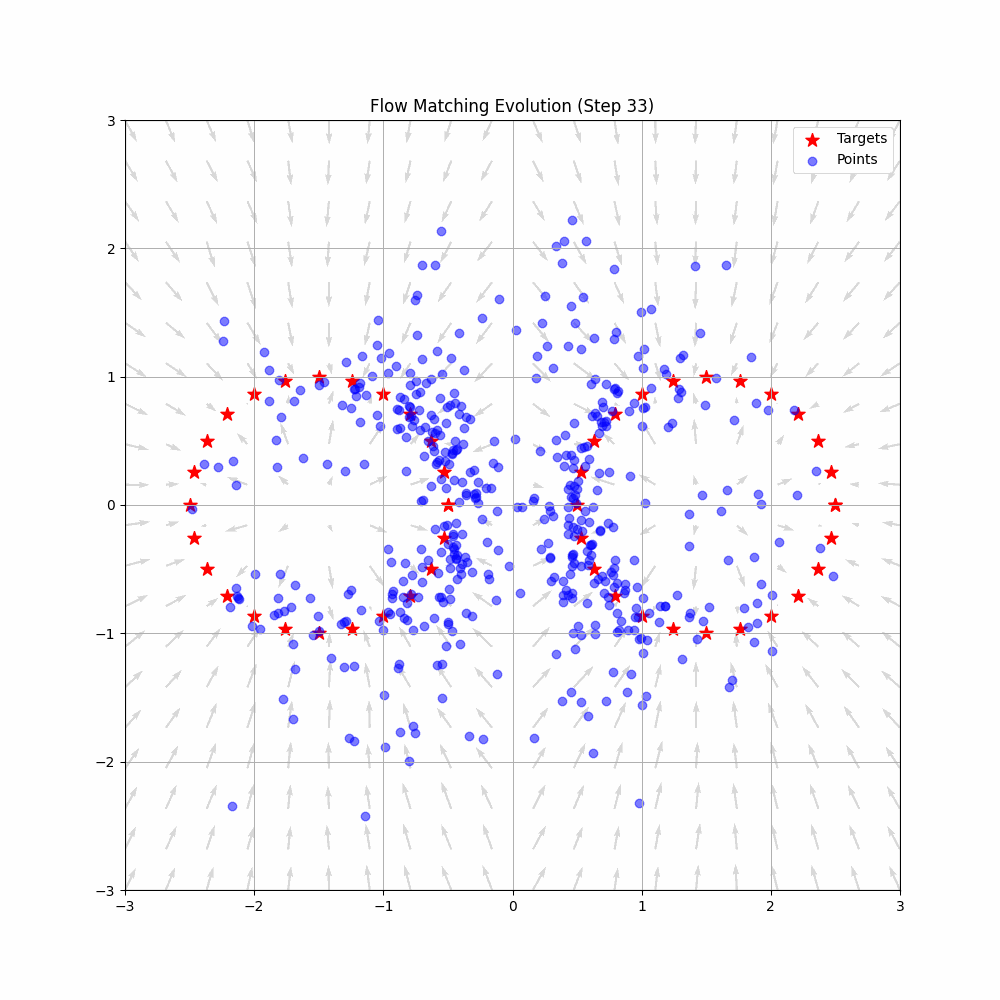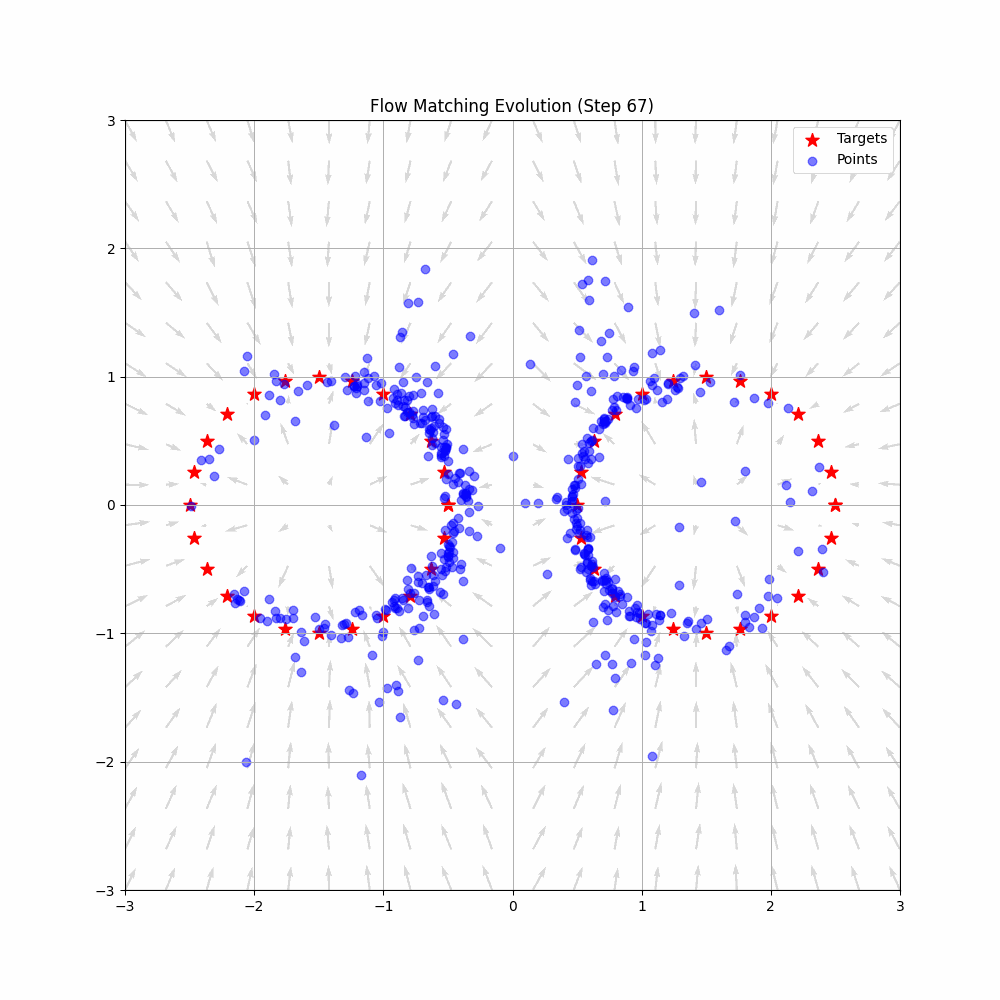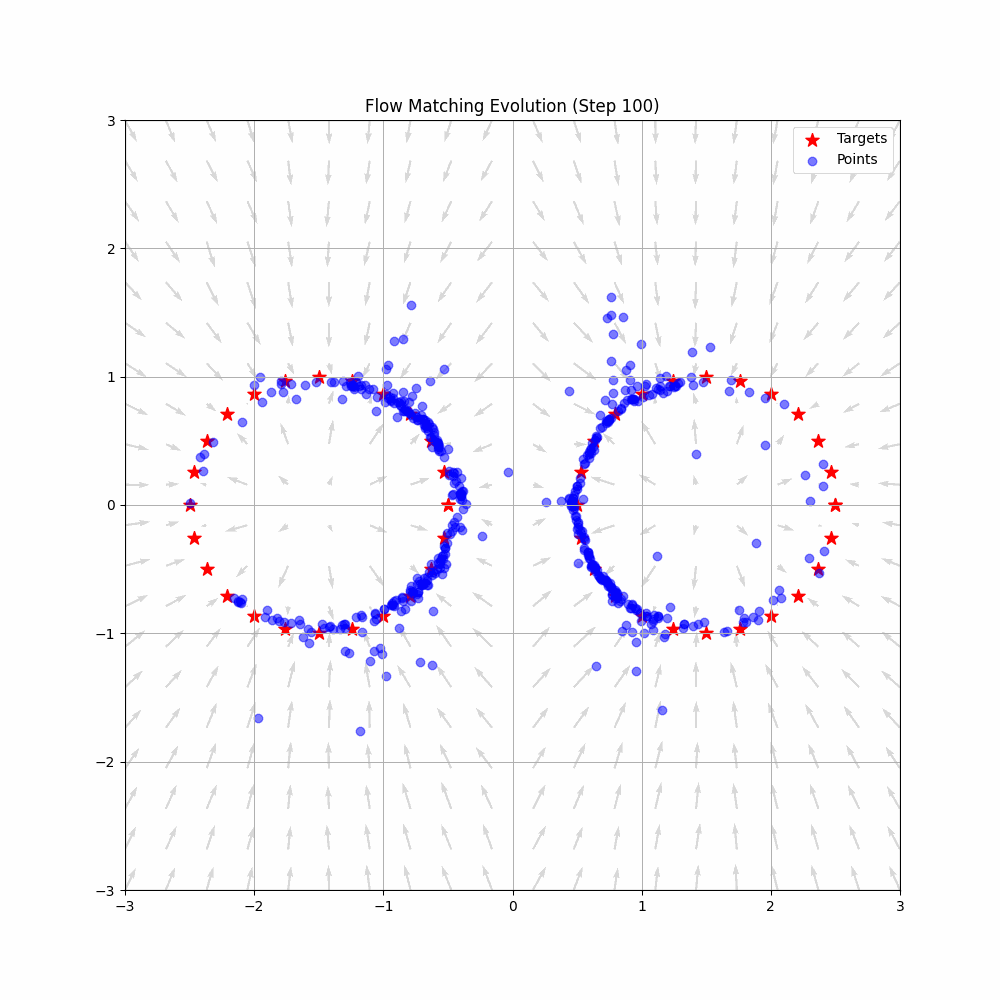
VLAPhysical Intelligence
π*0.6 and RECAP: Teaching Robots to Learn From Their Mistakes
A deep dive into Physical Intelligence's π*0.6 model and the RECAP method - an elegant technique that enables Vision-Language-Action models to improve through reinforcement learning without requiring policy gradients.
Read Article